Replication In Master Slave Architecture
In a single master and multiple slave architecture
- When the client sends a write request the request goes to the master. The master then updates its own replica of database and sends the update to all its followers. The master then sends a response to client that the database has been updated.
- Read requests is redirected to any of the node since all the nodes should have same replica. This increases the scalability of the system for read requests.
Synchronous vs Asynchronous
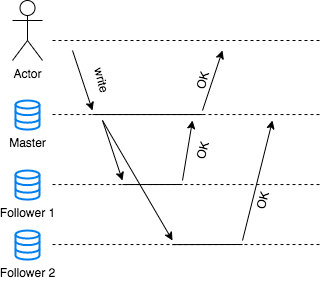
Above figure shows the various components of the system and interaction between them when a write happens. The client sends a write request to master which updates its own copy. The master then forwards the replication log or data stream to followers for them to update their replica. The figure shows that there is a significant delay in the response of follower 2. There is no guarantee how long it would take for every follower to update it’s replica. Hence, although the advantage of synchronous updates guarantee that all the replicas has been updated, it is impractical. The leader will wait for followers to respond and block all the write requests and failure of a single node can bring down the whole system to a halt.
In semi-synchronous system, there is usually one synchronous follower and others are asynchronous. If the synchronous follower crashes one of the asynchronous follower becomes a synchronous follower. If the master fails, the synchronous followers becomes the new leader.
In fully-asynchronous system, the leader continue accepting writes even if all the followers fall behind. But if the leader fails all the writes that are not updates in followers are lost.
Setting Up New Followers
If you need to scale your system by adding new replicas, a downtime is required since master is continuously accepting write requests. This means you might not meet your availability goals. However this can also be achieved without downtime.
- First, you take a snapshot of database and use it to load data in the new follower.
- Then the follower requests all the write request that happened after the snapshot was taken.
- The follower is then ready to accept read request and replicate subsequent writes by master.
Reference: Designing Data-Intensive Applications by Martin Kleppmann